
The data lifecycle consists of three stages- data creation stage, data processing stage and data reporting and insights stage. The complication is that database processing often occurs in silos, typically through applications such as ERP or CRM systems.These applications generate data in various formats.This silo effect hinders the creation of a unified data view, crucial for comprehensive analysis and decision-making. Things are further complicated by the rapid growth in the data. It is estimated that by 2025 we will have 180 zettabytes of data as compared to 60 zettabytes in 2020. The purpose of any data warehouse or data lake or data lake house is to combine data from several data sources to create a unified view of that data.
Data is typically divided into three categories: Structured data, Semi-structured and Unstructured data.
- Structured Data
Structured data can be normalized and it can be put into relational database and then manipulated using SQL or the structured query language data is easy to retrieve, update, delete and analyze. For example: Data that comes from the CRM or an ERP application including customer records, product inventory and financial data is all structured data.
- Semi-structured Data
Semi-structured data cannot be normalized but have some consistent properties as well as variable elements. For example: JSON, XML, HTML and Emails. Semi-structured data is typically stored in a NoSQL database which doesn’t have a relational schema, making it more flexible but harder to retrieve and manipulate data.
- Unstructured Data
Unstructured information has no predefined format or structure and cannot easily be queried, analyzed or manipulated. It is typically stored in its native format and requires specialist tools for any kind of meaningful extraction or manipulation. For example: text files, documents, spreadsheets, audio, video and social media posts. You can put unstructured data into structure data such as a Blob (Binary Large Object) but once you put unstructured data into a blob it cannot be accessed or manipulated.
In the context of the data types, let’s now deep dive into the concept of a Data Warehouse, Data Lake and Data Lakehouse.
- Data Warehouses: The Veteran Solution
The concept of the data warehouse emerged in the 1980s as databases matured, primarily serving as OLTP (Online Transaction Processing) systems. These systems were adept at handling transactional data from various business operations, such as billing by vendors. However, they fell short in providing business insights, such as identifying high-demand products, customer buying behavior, or products that were not selling. Traditionally, this gap was bridged by manually feeding data into Excel to extract insights.
This limitation led to the development of OLAP (Online Analytical Processing) systems and the broader concept of data warehousing. Data warehousing involves consolidating data from diverse sources, including CRM systems, sales data, Excel files, and CSVs. This consolidation is achieved through ETL (Extract, Transform, Load) technology, a now-common term that encapsulates extracting data, understanding and applying business requirements, transforming the data accordingly, and then loading it into a data warehouse. Once in the data warehouse, data is aggregated and summarized to a level that facilitates business insight generation. Various analytics platforms, dashboards, and data mining tools then connect to the data warehouse to glean insights.
However, data warehouses faced challenges as data types evolved. Initially designed to handle structured data compliant with ACID (Atomicity, Consistency, Isolation, Durability) principles and specific to databases, the advent of semi-structured and unstructured data from sources like sensors and social media posed new challenges. These data types, which the traditional data warehouse platforms were not equipped to process, necessitated the evolution of data warehousing practices to accommodate a wider range of data.
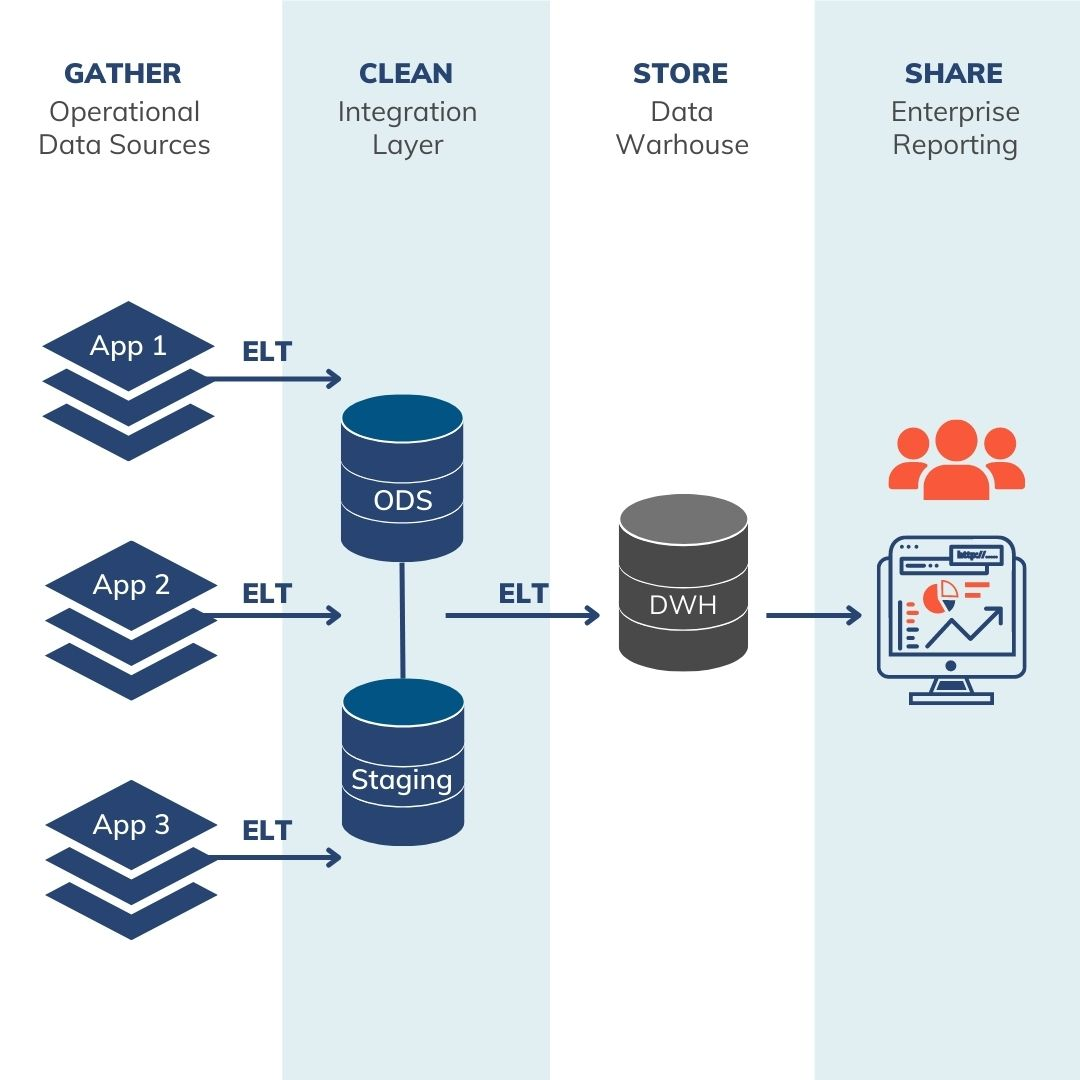
Source:https://www.analytics8.com/blog/what-is-a-data-warehouse/
- Data Lakes: The Flexible Repository
Data lake has emerged as a new solution to the above problem, offering a different approach to data storage. In a data lake, data is accepted in whatever format it arrives, adhering to the principle of “extract and load first, then transform as needed.” This flexibility allows for the collection of data from a wide range of sources, including platforms like YouTube, CRM systems, Twitter, and various sensor devices. The data, whether raw, unstructured, semi-structured, or fully structured, is collected without pre-judgment of its business utility. The primary goal is to gather and store the data in the data lake in its raw form. Subsequent transformations are applied based on specific needs of different use cases of machine learning (ML), AI, business intelligence, and third-party data access via APIs.
Data lakes are designed to accommodate any type of data, not limited to ACID-compliant databases. They leverage object storage services, such as Google Cloud Storage or Amazon S3, to store diverse data types, including images, CSVs, and video files. This data can then be selectively processed for various applications, including further analysis in a data warehouse or for business intelligence and AI/ML projects. The key advantages of data lakes over data warehouses include cost-effectiveness and speed, resulting due to the absence of upfront business logic application during the initial data collection phase.
However, data lakes are a relatively new and evolving concept with potential downsides. Without effective management and governance, a data lake can become a “data swamp,” where the sheer volume and poor quality of stored data obscure its value and utility. Issues such as data duplication and low-quality data can arise, challenging the discernment of data’s original purpose. Therefore, maintaining high data quality and robust data governance are crucial considerations for ensuring that a data lake remains a valuable asset rather than a liability.
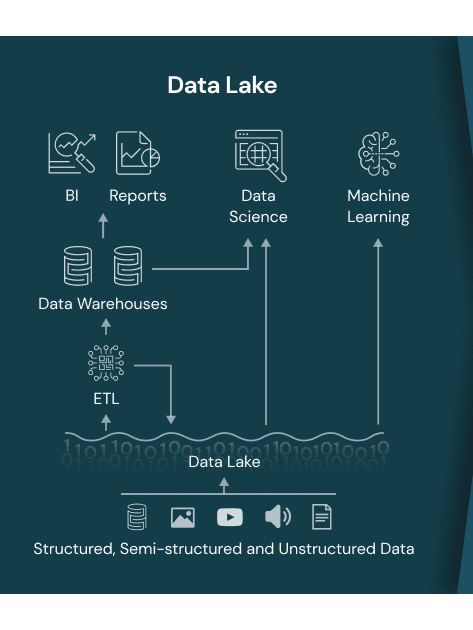
Source: https://www.databricks.com/blog/2020/01/30/what-is-a-data-lakehouse.html
- Data Lakehouses: Best of Both Worlds
The data lakehouse merges the strengths of both data warehouses and data lakes, offering a unified architecture that can handle both batch and real-time data. This innovative structure allows for the storage of ACID-compliant data typically found in warehouses as well as unstructured or semi-structured data common in data lakes, depending on the nature of the data. The integration between data warehouses and lakes within a lakehouse ensures seamless access to data across both platforms, further enhanced by a shared data catalog. This catalog acts as a marketplace, showcasing available data from both sources and enabling the application of SQL-based ETL queries on-the-fly through a “schema on read” approach. This method allows for rapid data analysis and the combination of insights from both structured warehouse data and more flexible lake data.
Additionally, the use of tools like Apache Spark facilitates the processing of large datasets for AI or ML projects directly within the data lakehouse, supported by near-time ETL capabilities that provide up-to-date insights much faster than traditional ETL processes. This blend of features from both worlds shows the lakehouse’s appeal, particularly its efficiency in data governance and quality management across diverse data types.
Despite being a relatively new concept, the data lakehouse represents a cost-effective solution to harness the full potential of an organization’s data. Platforms like Microsoft Azure, AWS, and Google Cloud are already enabling the creation of data lake houses, offering a glimpse into the future of data management. As this concept continues to evolve, its development promises to revolutionize how we store, access, and analyze data, making it an exciting area for exploration and growth in the data field.
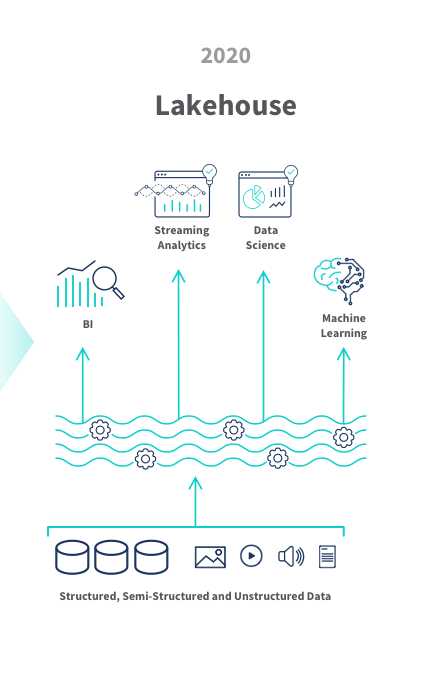
Source: https://insightsoftware.com/blog/remodel-your-oracle-cloud-data-with-a-data-lakehouse/