
Over the years, the data ecosystem has evolved and come a long way from what it was in the 1980s and 1990s. It evolved primarily to solve the problems of the previous stacks but ended up creating problems of its own. The famous Modern Data Stack is the biggest example of how, while solving problems of the previous stack, it created much bigger problems. Let’s go through the journey of evolution for the stack and see how we arrived at the mess we are in today.
The Traditional Data Stack
Historically, data has been an omnipresent force. The traditional data stack, our initial foray into taming this force, was a landmark in operationalizing data to enhance business outcomes. Yet, as our capacity to generate data increased—driven by innovations like IoT devices—the traditional stack’s limitations became apparent.
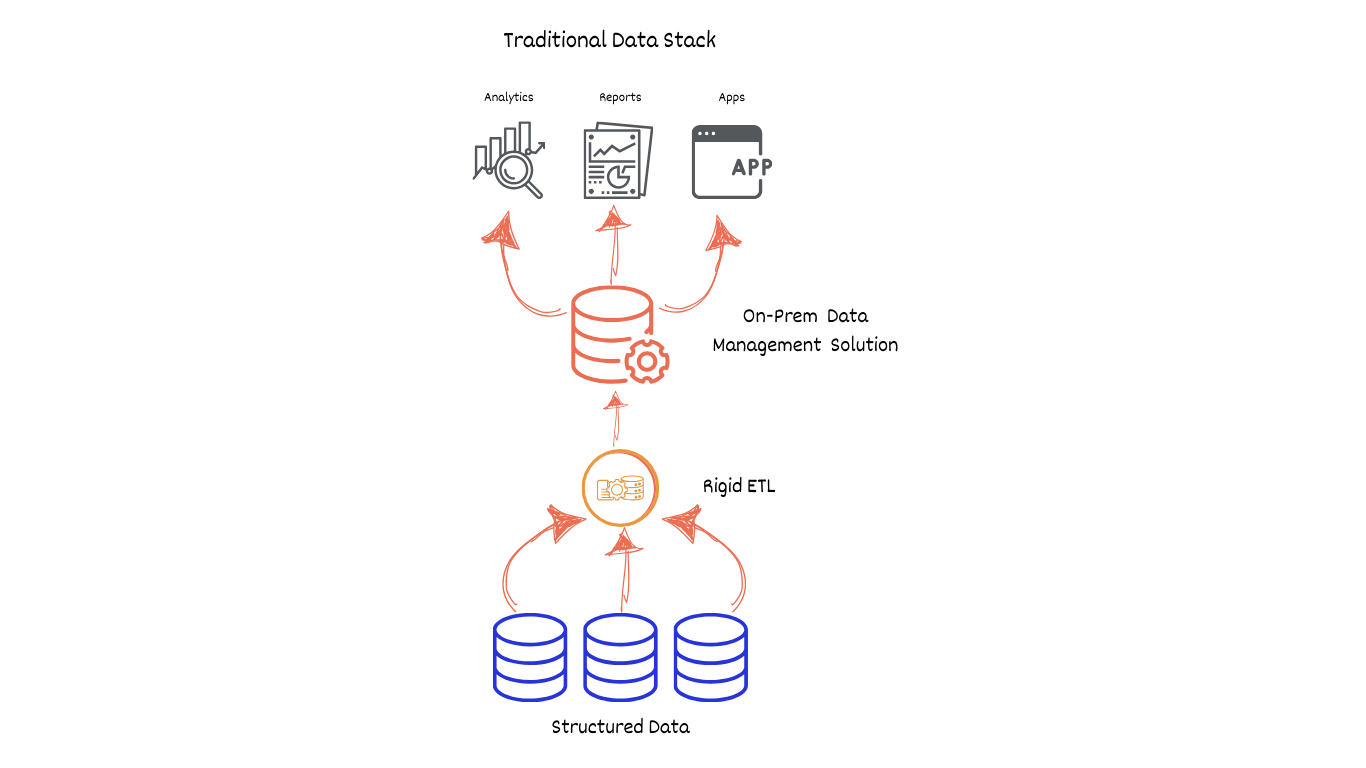
Traditional stack data systems were on-premise. Companies were responsible for overseeing their infrastructure and hardware. This resulted in high maintenance cost due to extensive manual work, limitations in scalability due to requirement of new on-prem infrastructure along with other challenges like the system being inflexible and fragile.
These challenges rendered Traditional Data Stack obsolete. Businesses were strangled by a system that was slow to adapt, costly to maintain, and brittle in the face of ever-changing data landscape, significantly impacting ROI and business agility.
Next-Gen Data Management: The Rise of the Modern Data Stack
To counter these challenges, the data stack had to evolve. And evolve it did – into the “ Modern Data Stack”. The modern data stack emerged as a beacon of hope, bringing about a shift to a cloud-based, scalable, and accessible data management.
The modern data stack is an integration of different technologies designed to address the end-to-end needs of the data ecosystem in the cloud era. It is characterized by its modularity, scalability, and efficiency, enabling organizations to swiftly adapt to changing data landscapes.
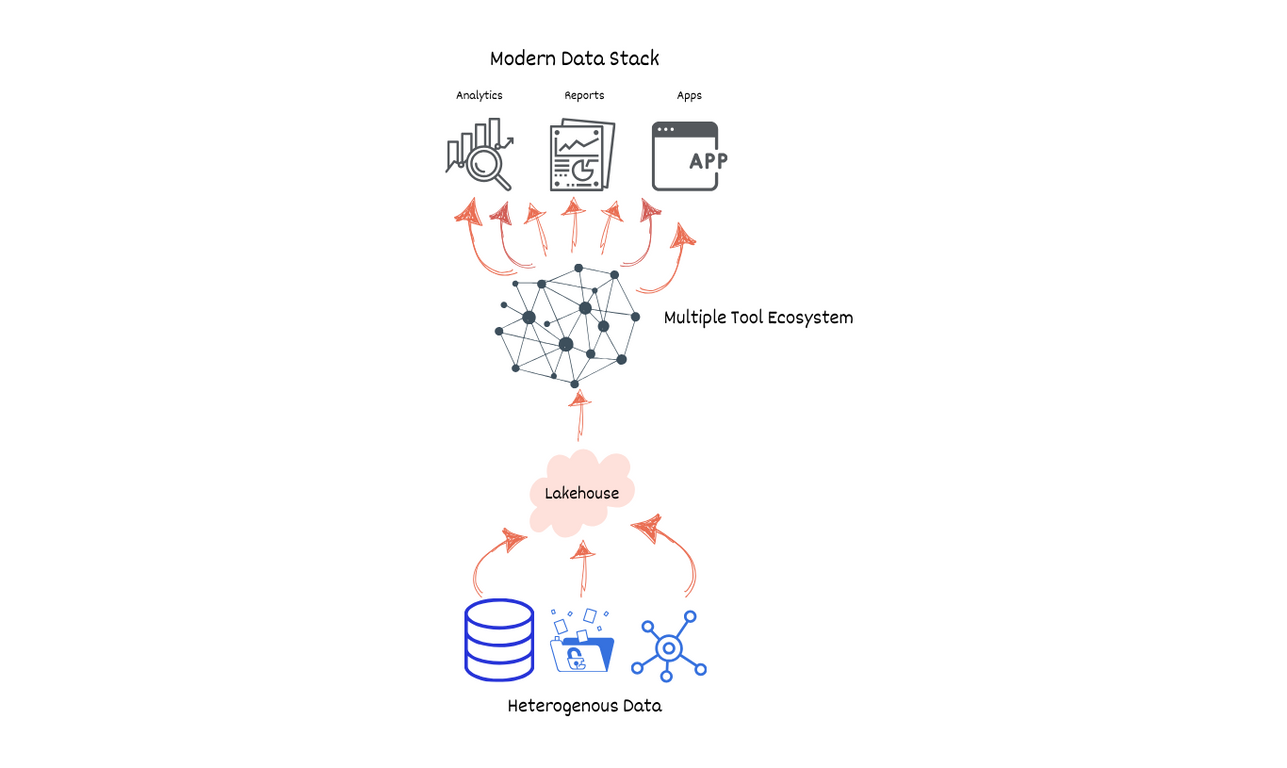
It uses a variety of components – Data Ingestion Tools like Stitch and Fivetran, Data Warehouse like Snowflake, Google BigQuery, and Amazon Redshift, Data Transformation Technologies such as dbt, Data Analysis and BI Tools like Looker, Tableau, and PowerBI and Data Orchestration and Automation Systems like Apache Airflow and Prefect, promising a more comprehensive data solution. Phew.
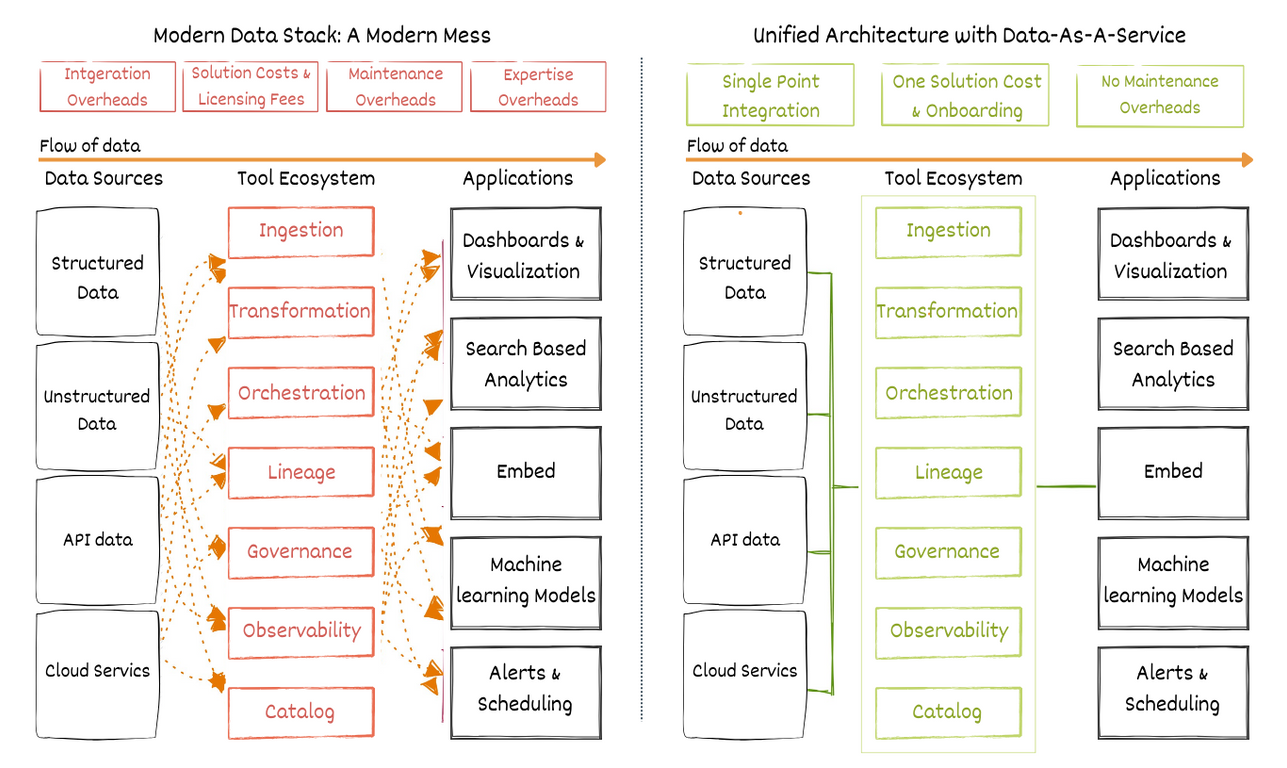
Even though MDS is a significant shift in data handling, promising a seamless flow from data to insights, it has resulted in a fragmented collection of tools that overcomplicate data pipelines and lead to data swamps—repositories of unutilized and overwhelming data volumes.
The charm of the MDS lies in that it addresses specific infrastructure issues within data ecosystems. However, its practical implementation reveals a double-edged sword.
- Integration Complexity: The MDS involves multiple point solutions, each designed to address specific processes in the data workflow. However, integrating these solutions can be highly complex. Different tools often have distinct interfaces and data format requirements, leading to significant overhead just to ensure these tools work harmoniously together. This not only increases the initial setup time but also complicates daily management as each integration point becomes a potential failure point in the system.
- Maintenance Overhead: Each component of the MDS requires regular updates, monitoring, and maintenance to ensure optimal performance and security. As the stack grows with more tools, this maintenance effort across all the tools can overwhelm data teams. This distraction, in turn, diverts focus away from core business objectives, as teams spend more time fixing and tweaking tools rather than deriving value from the data.
- High Resource and Financial Costs: Implementing a full suite of MDS tools often involves significant costs. These include not just the licensing fees but also the infrastructure costs associated with running them. Also, as each new tool adds layers of complexity, the need for specialized personnel to manage these tools increases, adding to the overall cost in terms of hiring and training.
- Data Silos: Despite the promise of integration, the MDS can inadvertently lead to the creation of data silos. This happens when data remains trapped within specific tools or departments, unable to be accessed or shared across the organization. Such silos can hinder collaboration and prevent the organization from achieving a unified view of its data.
- Scalability Issues: As organizations grow, their data needs evolve. The MDS, with its rigid structure of interdependent tools, can struggle to scale efficiently. Scaling might require additional configurations, integrations, or even a complete overhaul of the stack to accommodate new data types or processing capabilities, leading to potential disruptions and requirements for investments.
- Data Quality and Consistency Issues: With multiple tools handling different stages of the data lifecycle, ensuring consistent data quality and format across the stack can be challenging. Inconsistencies can lead to errors in data analysis and business reporting, potentially leading to misguided business decisions.
- Complexity in Data Governance: Ensuring compliance with data governance policies and regulations becomes more complex with an MDS. Each tool in the stack may have its own method of handling data security and privacy, requiring detailed oversight to ensure that the entire stack complies with regulatory standards and internal policies.
As data ecosystems evolve into increasingly intricate and isolated systems, they are becoming more challenging for non-expert end users, especially with the frequent addition of specialized point solutions. This complexity has aptly earned the ecosystem the nickname “the MAD (ML, AI, & Data) landscape.” An infographic by Matt Turck highlights the issues with MDS, effectively demonstrating the problem without the need for text — indeed, a picture is worth a thousand words!

The MAD Ecosystem | Source: mattturck.com
The New Age: Dataset-As-A-Service
The Dataset-As-A-Service represents a paradigm shift, as it prioritizes data and data-driven decisions above all, addressing the pitfalls of the modern data stack by advocating for a unified, non-disruptive approach. This approach enhances integration, minimizes complexity, and dramatically accelerates time to ROI.
This innovative approach involves trusted, reusable data models that abstract the complexities of underlying data sources — whether structured, unstructured, real-time, or batch.
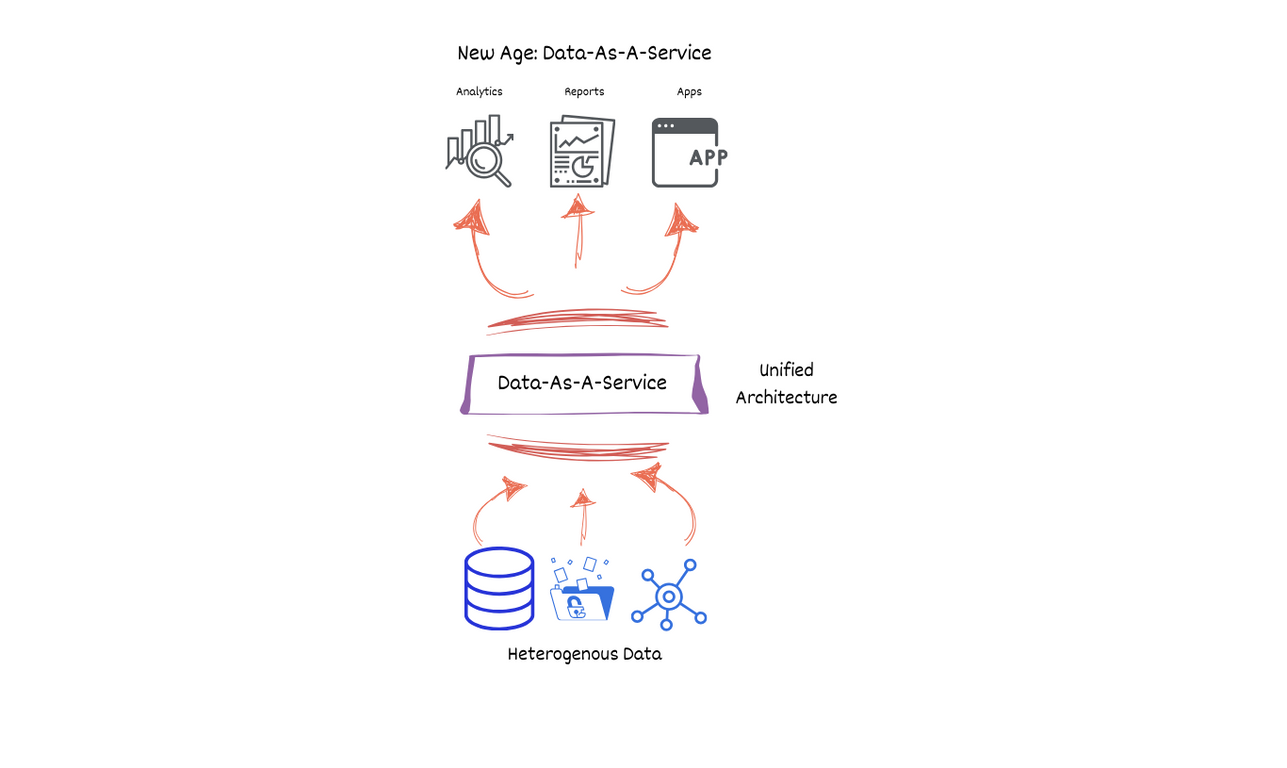
Advantages of Dataset-As-A-Service
- Unified Data Access: DAAS allows for direct connections to SQL and NoSQL databases, existing data warehouses, and any data accessible via API. It works on schema-on-read methodology, supporting data joining across different sources, such as combining data from Elasticsearch with a MySQL database, enabling powerful and flexible data querying capabilities.
- One place for all Security and Governance: Security and governance is managed in one place, and the platform integrates them directly into the data sets, ensuring that data management is compliant with regulatory standards and secure from unauthorized access.
- Reducing Complexity and Costs: DAAS approach cuts through the traditional complexities of data management by eliminating the need for multiple intermediary tools. By simplifying the data pipeline — from data ingestion to actionable insights — it reduces the reliance on transportation, transformation, and storage tools, which in turn decreases both costs and operational complexities.
Knowi Approach
Knowi is the first analytics platform that natively supports and understands both traditional and non-traditional structures. Using structured data, data engineers may quickly see insights without moving or transforming the data first.
By retaining existing data and obviating the necessity for data and ETL prep, Knowi dramatically cuts the price, time to market, and the difficulty of your analytics initiatives.
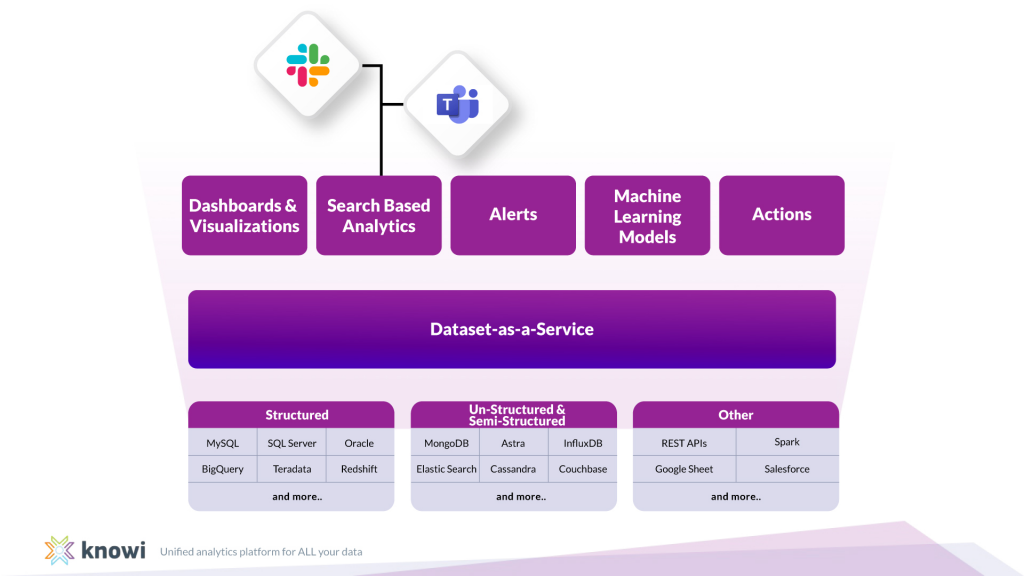
Knowi has the Dataset-As-A-Service layer that allows native connection to your data source(s), runs a schema-on-read to rapidly identify data, and enables you analyze and visualize your data immediately.
All in all, Knowi is a platform for unified analytics without the requirement for unified data. It does away with conventional ETL and the need to keep raw data in a data warehouse.