
Elasticsearch is an open-source, distributed data search engine that has been blowing up in popularity – Here’s the 411 on what you should know
These days, due to digitalization, unstructured data is getting generated at a higher volume and velocity than ever before. Organizations are sitting on tons of unstructured data, but retrieving effective information from this data is not an easy task. Elasticsearch is a popular document-oriented search engine that is well known for its ability to search and retrieve both unstructured and structured data fast and efficiently.
In this article, I will give a simplified introduction to Elastic search and by the end of this, beginners will be able to understand its advantage, architecture, and some notable use cases.
TL;DR
- Elasticsearch is an open-source, distributed search and analytics engine built on Apache Lucene, designed for fast full-text search across large volumes of unstructured data.
- Its core use cases are application search, log and event data analysis, security analytics, business intelligence, and geospatial data queries.
- The ELK Stack (Elasticsearch, Logstash, Kibana) is widely used for log aggregation and monitoring, though Kibana has limited visualization options for business dashboards.
- Knowi connects natively to Elasticsearch to build dashboards and run analytics without Kibana, giving teams SQL-like access to ES indices.
Table of Contents
What is Elasticsearch?
There are plenty of NoSQL databases like MongoDB, PostgreSQL, Solr that can be used to store and query unstructured data. However, these NoSQL databases have limited capabilities for executing complex queries and often they do not perform well for real-time information retrieval. This is where Elasticsearch comes into the picture to fill the gap.
Elasticsearch is an open-source, distributed search engine with analytics capability. It is built on top of the Lucene framework and is written in Java. Right from its initial release in 2010 by its creator Shay Banon, Elasticsearch garnered positive attention from developers and companies alike. Its rise in popularity was largely due to its powerful search engine that could literally search any type of data that includes textual, numerical, geospatial, structured, and unstructured.
Unlike NoSQL databases, Elasticsearch is primarily designed to be a search engine, instead of a datastore. It has amazing capabilities to perform fast, almost real-time, and advanced searches. Usually, it is integrated on top of other databases, but Elasticsearch can also be used as a datastore itself.
Another powerful and much-liked feature of Elasticsearch is that the searches can be done using its powerful Restful APIs hence making it quite easy for other systems to integrate with it.
Architecture of Elasticsearch
Let’s take a quick look at the different components of the Elasticsearch architecture one by one.
Document and Types
A Document is the basic unit of data in Elasticsearch. Documents are saved in JSON format, can have multiple properties, and are associated with a Type. For example, if we want to add data regarding an e-commerce product then we can create a document object of type ‘Product’ with properties like Name, Description, Price, Reviews. Similarly, we can create documents of Customer type that may have properties like Name, Contact, Address, Order History.
For those who are from SQL background, they may relate Types as Tables of RDBMS, Document as Rows of Tables, and Properties as Columns of tables.
It should be noted however that Elasticsearch has plans to phase out the concept of Types. They have already limited the usage of Types in Elastic 6.0 and furthermore in 7.0
Elasticsearch Index
Logically related documents or those documents that have similar characteristics are organized under a common collection known as an Index. In our example, all the Product documents would be tied to one Index and all Customer documents to another index.
An index is analogous to the Database in RDBMS. However, do note that all our analogies with RDBMS are for easy understanding and it is not to say that Elasticsearch works like RDBMS.
Inverted Index
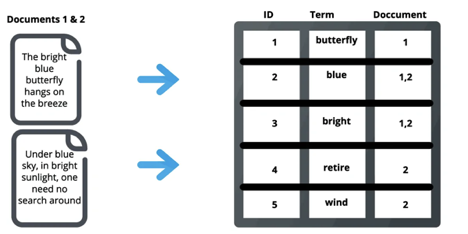
Once the documents are indexed, Elasticsearch creates a data structure known as the Inverted Index which is primarily responsible for the lightning-fast search result retrieval. Simply put, the inverted index contains the terms along with the information in which all documents each of these terms are present. The below illustration will make this clear. For example, if the term ‘blue’ is searched, Elastic search will do a lookup in the inverted index and quickly return documents 1 and 2.
Nodes and Clusters
In Elasticsearch, data is distributed across multiple servers known as Nodes. When a query is fired, the result of search data has to be consolidated from multiple nodes. The collection of all these nodes is called a Cluster.
Sharding and Replication
Elasticsearch breaks down an index into multiple shards, where each shard is a fully functional index in itself that is saved on one node. Sharding helps to distribute the resources required for indexes horizontally across multiple nodes and also ensures easy scalability in the future.
Another very important feature of Elasticsearch is the replication of shards across multiple nodes on the cluster to increase fault tolerance. If a node has failed due to any reason, then due to the replication of shards, the same data is available on another node.
What is Elastic stack (Formerly ELK Stack)
An introduction of Elasticsearch cannot be complete without touching upon Elastic Stack. Elasticsearch is a general-purpose document search engine that can work in a standalone role. However, around the same time ES was created in the early 2010s a data ingestion tool called Logstash was created by Jordan Sissel and was getting traction for its ability to ingest log data into any target systems, one of which was Elasticsearch.
Also on the scene was a visualization tool called Kibana. Kibana was being developed by Rashid Khan so it could be used to visualize log data effectively. People were finding these three tools highly useful for the common use case of log search and log analytics. So the three product owners decided to join the forces in 2012 and officially formed ELK stack i.e. Elasticsearch, Logstash, Kibana stack. This name was later rebranded to Elastic Stack. The Elastic Stack has since become well known in the data engineering world.
Challenges with Kibana
Although Kibana remains a popular option for the visualization component a couple of other options with more features have recently cropped up. See the comparison of Kibana vs Grafana vs Knowi here.
The reason for this is that although Kibana is an incredibly good fit for visualizing log data in Elasticsearch, the use cases for Elastic have grown far beyond their original log data origins (see the section below on use cases).
Because of this expansion of scope, Kibana
Why Elasticsearch is Popular
As per this survey from Stackshare, the following are the top reasons why developers and companies choose Elasticsearch:
- Powerful API
- Great search engine
- Open source
- Restful
- Near real-time search
- Free
- Search everything
- Easy to get started
- Analytics
- Distributed
Use Cases for Elasticsearch
Elasticsearch has popular use cases for log search and analytics, application monitoring, web search, application search, business analytics. There are many well-known companies and enterprises that are using Elasticsearch, let us take a look at some of the variety of use cases.
● Pfizer uses Elasticsearch on top of their data lake called Scientific Data Cloud (SDC) for performing audits, searches, and near real-time dashboard reporting.
● The New York Times is leveraging Elasticsearch to search through 15 million articles of its last 160 years of publication history.
● Ebay is using Elasticsearch to search through 800 million product listings within a few seconds.
● Groupon is making use of Elastic search to retrieve the most relevant local deals for its customers.
● GoDaddy is using Elasticsearch with its built-in machine learning feature to detect anomaly in their logs to provide better customer experience.
Conclusion
If you are a beginner, this article would have given you a high-level understanding of Elasticsearch and its features. We also scratched the surface of its ecosystem of ELK along with some of its real-world industry use cases. We hope this will serve as a motivation and stepping stone for you to adopt Elasticsearch for your project requirements.
Elasticsearch Use Cases at a Glance
| Use Case | What Elasticsearch Does | Example |
|---|---|---|
| Full-text search | Indexes and ranks documents by relevance using inverted index | E-commerce product search, site search |
| Log and event analytics | Ingests and queries high-volume time-series log data in real time | Application monitoring, error tracking (ELK Stack) |
| Security analytics (SIEM) | Correlates security events across sources to detect threats | Intrusion detection, compliance reporting |
| Geospatial search | Stores and queries location data with geo_point and geo_shape fields | Nearest-store finder, delivery route optimization |
| Business intelligence | Aggregates metrics across millions of documents in milliseconds | Revenue dashboards, customer behavior analytics |
| Autocomplete and typeahead | Suggests search terms as users type using edge n-gram tokenizer | Search bars, address lookup |
Knowi connects natively to Elasticsearch and lets you build dashboards directly on your ES indices without writing custom Kibana visualizations. Book a demo to see it in action.
Related Resources
- What is Elasticsearch? A Complete Guide
- Elasticsearch vs MySQL
- Kibana Overview and Alternatives
- Elasticsearch vs MongoDB
Frequently Asked Questions
What is Elasticsearch used for?
Elasticsearch is used for full-text search, log and event analytics, security analytics (SIEM), geospatial queries, business intelligence dashboards, and autocomplete features.
Is Elasticsearch a database?
Elasticsearch is a search and analytics engine, not a traditional relational database. It stores data as JSON documents in indices and excels at full-text search and aggregations. It lacks ACID transactions and relational joins.
What is the difference between Elasticsearch and Kibana?
Elasticsearch is the search and storage engine. Kibana is the visualization front-end for the Elastic Stack. Kibana is optimized for log dashboards; for business intelligence, tools like Knowi provide more flexibility with native ES connectivity.
How does Elasticsearch store data?
Elasticsearch stores data as JSON documents grouped into indices, divided into shards (horizontal scaling) with replica copies (fault tolerance). The inverted index within each shard maps every unique term to the documents containing it.
What is the ELK Stack?
The ELK Stack is Elasticsearch (search and storage), Logstash (data ingestion pipeline), and Kibana (visualization). It is widely used for centralized log aggregation and application monitoring.