
AWS Glue is a fully managed serverless ETL (Extract, Transform, Load) service that discovers, catalogs, and transforms data across AWS data stores without requiring you to manage any infrastructure.
TL;DR
- AWS Glue is a serverless ETL service that automatically discovers schema (Data Catalog), generates transformation code in PySpark or Python, and loads data into S3, Redshift, RDS, and other targets.
- The Glue Data Catalog is a central metadata repository that Athena, Redshift Spectrum, and EMR can all query.
- Glue Crawlers scan data sources on a schedule and update the Data Catalog automatically when schemas change.
- For analytics on top of Glue-processed data, Knowi connects directly to S3, Redshift, and other Glue targets without additional ETL.
Table of Contents
- What is AWS Glue and do you need it?
- What is ETL Process?
- Key Challenges with ETL process
- Introduction to Amazon AWS Glue
- Advantage of AWS Amazon Glue
- Companies Using AWS Glue
- Is Amazon AWS Glue For You?
- Data Virtualization – The No ETL Solution
- Conclusion
- AWS Glue vs Alternatives
- Related Resources
- Frequently Asked Questions
What is AWS Glue and do you need it?
Amazon AWS Glue is a fully managed cloud-based ETL service that is available in the AWS ecosystem. It was launched by Amazon AWS in August 2017, which was around the same time when the hype of Big Data was fizzling out due to companies’ inability to implement Big Data projects successfully. In 2015, Gartner had made a famous prediction that 60% of Big Data projects would fail by 2017, although its analyst later claimed that the figure was conservative and actual failure rate could be as high as 85%.
Among many factors behind the failures, in the same report, Gartner highlighted that lack of correct IT and infrastructure skills would be a key factor behind failures of such big data analytics projects. If we elaborate on this point, one of the main challenges of any big data project is to bring a variety of data from multiple sources into the central data lake or data warehouse. This often requires implementation and managing of complex ETL processes which is not a very easy task and can become a point of failure. So it was not just a mere coincidence that Amazon AWS Glue was launched in 2017, rather, it was an attempt to capitalize on the fragile ETL market by making ETL available as a service on its cloud.
Before we explore Amazon AWS Glue closely, let’s first understand what exactly is ETL and what are the challenges associated with it. Then we’ll look at AWS Glue and its features. Lastly, we will touch on an alternative solution to building ETL pipelines: data virtualization.
What is ETL Process?
ETL stands for Extract, Transform, and Load, in this process, data is collected from various sources and loaded into a target database of Data Warehouse or Data Lake. The three main steps of the entire process are:
Extract
In this process, data from various sources are extracted and put into a staging area. The data can be extracted either from homogeneous sources or from heterogeneous sources. For example, it is quite possible that you are extracting some data from a SQL database and other data from the NoSQL database for your data lake.
Transform
The data extracted in the first step is usually kept in a staging area to clean it and preprocess it to make data from different sources consistent and make sure that they conform to the design of our target database. For example, while extracting the sales data from different countries it makes sense to convert the different currencies into a common currency like USD before inserting it in the target database.
Load
In this final step, the cleaned and preprocessed data is finally loaded into the target database of the data lake or data warehouse. The data is now available for you to perform analytics and draw insights from it.
Key Challenges with ETL process
- ETL has been around for many years now in some form or another. Before the big data explosion, ETL was considered to be a batch process that usually had to deal with homogeneous data only. Things were easy back then, but times have changed now with data coming with high volume, velocity, and variety, along with the growing expectation to perform near real-time ETL. All this demands a very complex ETL design which is a new type of challenge for the ETL developers.
- The growing complexity with ETL demands more sophisticated infrastructures, servers, and resources. A big enterprise can still afford to invest in on-premises powerful servers, but the smaller companies may not always find it easy to spend to build powerful ETL servers.
- ETL is not a reward but an overhead. This is because the final goal is to extract reports, meaningful insights, perform analytics on the data and ETL is just a prerequisite. This old survey of 2015 mentions that one-third of the respondents said they spend 50%-90% of their time in data preparation to make it “analytics-ready”. So paradoxically, companies whose main goal is to perform analytics end up spending more time and money in bringing data to the analysts and data scientists.
Introduction to Amazon AWS Glue
As we discussed in the introduction, Amazon AWS Glue is a fully managed and serverless ETL service available on the AWS cloud. Here “managed and serverless” means that AWS Glue will take care of the server and resource provisioning on the AWS Cloud on its own as per the need. So as a user you need not worry about the infrastructure part.
Let’s look at AWS Glue more in-depth with the help of its architecture.
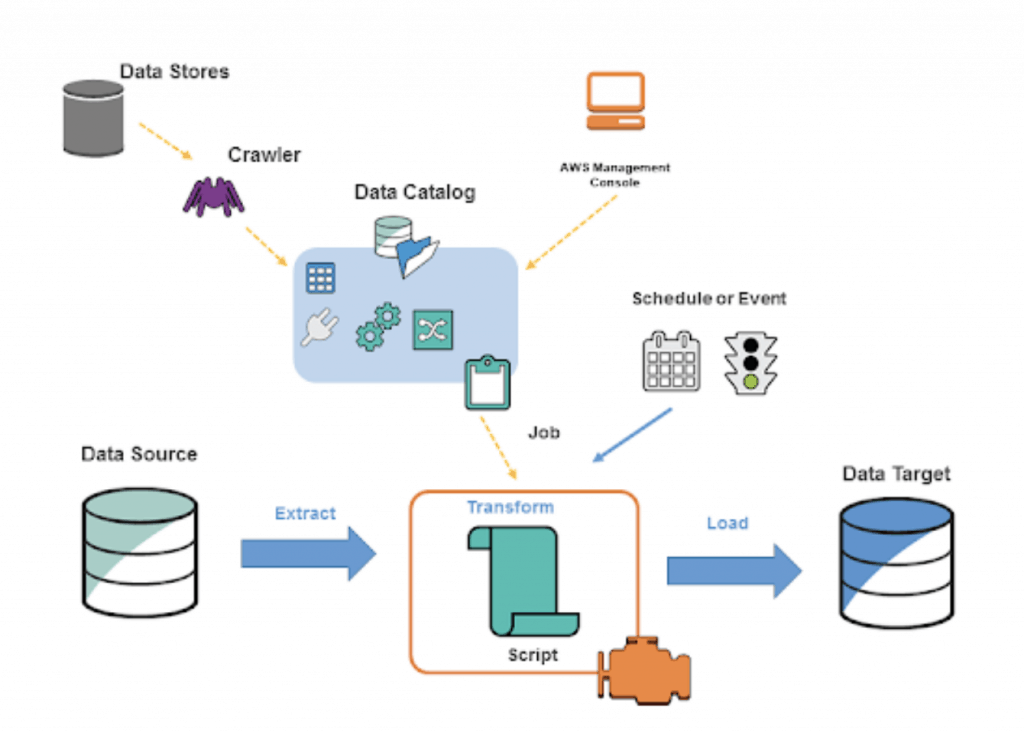
AWS Glue architecture consists of three main parts –
- AWS Glue Data Catalogue
- ETL Engine
- Schedulers
AWS Glue Data Catalog
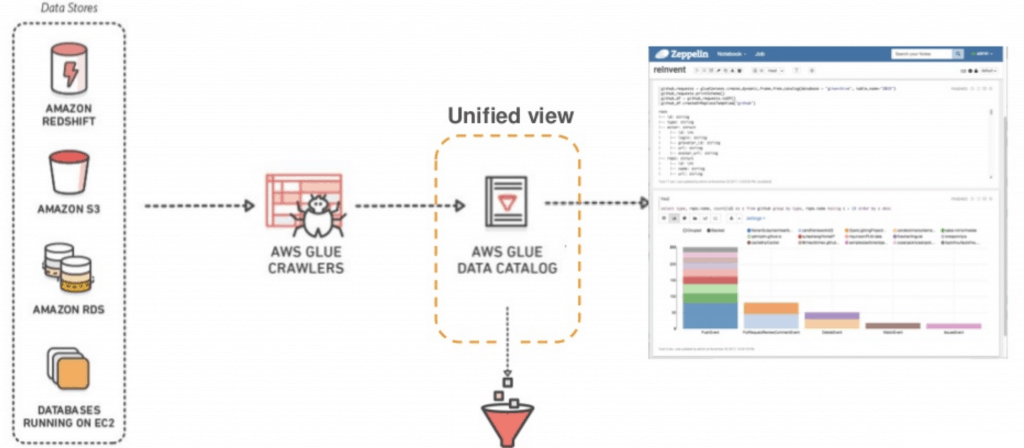
AWS Glue automatically browses through all the available data stores with the help of a crawler and saves their metadata in a central metadata repository known as Data Catalog. This metadata information is utilized during the actual ETL process and beside this, the catalog also holds metadata related to the ETL jobs.
There can be one or many data stores like Amazon RDS, Amazon Redshift, Amazon S3, and other databases running on EC2 instances. Once crawling is done, it creates a catalog of the data from various sources and presents a unified view that can be queried using Amazon Athena or Amazon Redshift Spectrum.
This catalog can also be used as a Hive Metastore in case you are working with big data on Amazon EMR. Needless to say, it supports all the popular data types and formats like CSV, JSON, Parquet to name the few.
ETL Engine
AWS Glue utilizes the catalog information and can automatically generate ETL scripts either in Scala or Python as per your choice. This ETL script is responsible for loading data from source data sources to the target data source, usually a data warehouse or data lake. You also have the flexibility to further customize as per your requirement.
{kind=link}
Schedulers
The ETL jobs can be invoked manually but for the recurring ETL jobs, AWS Glue provides Schedulers to execute the ETL process at scheduled frequencies. You also have the flexibility to chain multiple ETL jobs in a sequence of execution or trigger the job at a predefined event. What makes it more useful is that these schedulers can also be invoked from external services like AWS Lambda.

{kind=link}
Advantage of AWS Amazon Glue
At the start of this article, we presented you with the challenges of ETL, so let’s look at how AWS Glue has made life easier for the ETL process.
- Since AWS Glue is a cloud ETL service, the organizations don’t have to worry about investing in on-premises ETL infrastructures.
- Even on the AWS cloud, AWS Glue is fully managed and serverless, everything is taken care of on its own in the background. You don’t have to launch any server or services on AWS explicitly for the ETL process.
- Being a cloud ETL service, AWS Glue is a cost-effective option for large and small companies alike.
- You don’t have to spend much time in the ETL process, AWS Glue serves the ETL code to you on the plate. This means you can focus more on performing analytics on the data directly. Remember, doing analytics had always been the actual goal, with ETL being just a necessary evil to get the data in a format where that is possible.
Companies Using AWS Glue
Below are some of the well-known companies using AWS Glue –
- Deloitte
- Brut
- 21st Century Fox
- Siemens
- Finaccel
- Woot
- Robinhood
- Creditvidya
Is Amazon AWS Glue For You?
If you are a company that is already using AWS cloud for running your applications and are looking for an ETL solution, then you should definitely consider AWS Glue since you’re already within that ecosystem.
However, if your company is not using AWS cloud at all, it’s a little less clear cut. If your company is okay with investing time and money on building data lakes from scratch, it may make sense to migrate to AWS cloud and build your data lake there with the help of AWS Glue and the other services in the AWS ecosystem. But this certainly will not be the right fit for all use-cases.
Although Amazon Glue has been reducing the effort required in the ETL process, let us take a moment here and step back to ask another question – “Do we really need ETL ?” This question might sound counterintuitive in this article but there are some new no-ETL solutions that have recently entered the market.
Data Virtualization – The No ETL Solution
Data virtualization is a technique of retrieving or querying data from one or many data sources without having to worry about the underlying format of the data. This is possible due to the data virtualization layer. Since you are querying the data directly from the sources in real time, there is no need to perform ETL to load data into a data warehouse or data lake.
Data virtualization is definitely a game-changer since it is eliminating the very need for the ETL process and rendering even AWS Glue unnecessary for a number of use-cases. However, there are very few tools currently in the market that offer data virtualization. One tool that does this well our business intelligence platform, Knowi. Knowi is unique in the business intelligence space for having invested heavily in data virtualization from the start to eliminate the need for ETL–allowing customers to go straight to doing analytics on their data. If you want to give it a try you can do a free trial here.
Conclusion
ETL is the most challenging aspect for any data analytics project and it often becomes a complicated overhead if not the reason for failure. Amazon AWS Glue helps in streamlining the ETL process with it’s fully managed ETL service. However, for some use-cases, it may be more practical to use a BI tool like Knowi that eliminates the need for ETL using data virtualization.
AWS Glue vs Alternatives
| Tool | Type | Best For | Pricing |
|---|---|---|---|
| AWS Glue | Managed serverless ETL | AWS-native pipelines, Redshift/S3 targets | Pay per DPU-hour (Data Processing Unit) |
| AWS Glue Studio | Visual ETL builder on top of Glue | No-code/low-code pipeline creation | Same as Glue |
| Fivetran | Managed ELT connector | Pre-built connectors for 300+ SaaS sources | Per MAR (Monthly Active Rows) |
| Airbyte | Open-source ELT | Self-hosted or cloud, 300+ connectors | Free (self-hosted) or per connector (cloud) |
| dbt | Transformation layer (T in ELT) | SQL-based data modeling in the warehouse | Free (core) or per seat (Cloud) |
| Apache Spark | Open-source distributed ETL | Custom large-scale transformations | Open-source (infra cost) |
Once your data is in Redshift or S3 via Glue, Knowi connects natively to build dashboards without another ETL step. Book a demo to see the integration.
Related Resources
Frequently Asked Questions
What is AWS Glue used for?
AWS Glue is used to build serverless ETL pipelines on AWS: ingesting data from S3, RDS, or DynamoDB into Redshift or a data lake, cataloging schemas for Athena queries, and running PySpark transformations on a schedule.
What is the AWS Glue Data Catalog?
The Data Catalog is a central metadata repository that Glue Crawlers populate automatically by scanning your data sources. Athena, Redshift Spectrum, and EMR can query it without duplicating data.
What is the difference between AWS Glue and AWS Lambda for ETL?
Glue is purpose-built for large-scale ETL with auto-provisioned Spark clusters. Lambda is a general-purpose function runtime suited for lightweight tasks under 15 minutes. Use Glue for millions of rows; use Lambda for simple event-triggered tasks.
How does AWS Glue pricing work?
Glue charges per DPU-hour (4 vCPU, 16 GB RAM). ETL jobs have a 1-minute minimum, billed in 1-second increments. The Data Catalog is free for the first 1 million objects, then $1 per 100K objects per month.
What is the difference between ETL and ELT?
ETL transforms data before loading it into the destination. ELT loads raw data first, then transforms it inside the warehouse using tools like dbt. AWS Glue supports both patterns.